データベース 2日目

スクリプトファイルの作成
※Windowsのコマンドプロンプトからスクリプトファイルを読み込ませる場合はスクリプトファイルの文字コードをWindowsの標準文字コードである「Shift-JIS」に変換する。
文字化けした時
スクリプトファイルとは
複数のSQL文をテキストファイルに保存し、そのファイルをMariaDBに読み込ませて実行する。これにより効率的にDBを構築することができ、初期データの登録やテスト用DB領域の作り直しを簡単に行うことができる。
スクリプトファイルの作成
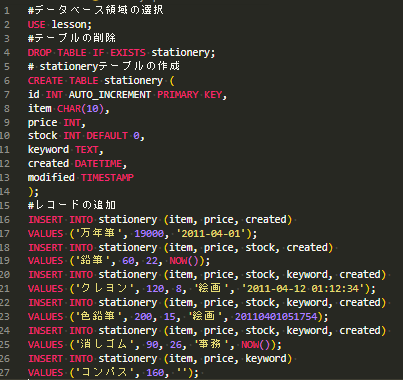
#データベース領域の選択
USE lesson;
#テーブルの削除
DROP TABLE IF EXISTS stationery;
-- 「もしstationeryテーブルが存在していたら削除する」というSQL文。
# stationeryテーブルの作成
CREATE TABLE stationery (
id INT AUTO_INCREMENT PRIMARY KEY,
item CHAR(10),
price INT,
stock INT DEFAULT 0,
keyword TEXT,
created DATETIME, --登録日を管理
modified TIMESTAMP --変更日を管理
);
#レコードの追加
INSERT INTO stationery (item, price, created)
VALUES ('万年筆', 19000, '2011-04-01');
INSERT INTO stationery (item, price, stock, created)
VALUES ('鉛筆', 60, 22, NOW());
INSERT INTO stationery (item, price, stock, keyword, created)
VALUES ('クレヨン', 120, 8, '絵画', '2011-04-12 01:12:34');
INSERT INTO stationery (item, price, stock, keyword, created)
VALUES ('色鉛筆', 200, 15, '絵画', 20110401051754);
INSERT INTO stationery (item, price, stock, keyword, created)
VALUES ('消しゴム', 90, 26, '事務', NOW());
INSERT INTO stationery (item, price, keyword)
VALUES ('コンパス', 160, '');DROP TABLE IF EXISTS テーブル名;
「もし既に同じ名前のテーブルが存在していたら削除する」というSQL文。
DROP TABLEはテーブルを削除するSQL文。
DATETIME型 TIMESTAMP型
登録日を管理するcrestedフィールドをDATETIME型、変更日を管理するmodifiedフィールドをTIMESTAMP型で作成している。
DATETIME型
DATETIME型は日付を管理する型で、決まった書式で記述する。
‘YYYY-MM-DD HH:MM:SS’ または YYYYMMDDHHMMSS 形式の値として記述する。時間を省略すると「00:00:00」となる。
INSERT INTO stationery (item, price, keyword)
VALUES ('コンパス', 160, '');登録した時間を自動的に取得する場合は「NOW()」を使用する。
INSERT INTO stationery (item, price, stock, created)
VALUES ('鉛筆', 60, 22, NOW());TIMESTAMP型
TIMESTAMP型はデータ変更時、自動的に日付を登録する型。
更新日の管理などに使われる。
スクリプトファイルの拡張子
拡張子「.sql」を使ったスクリプトファイルが多いが、どんな拡張子でもOK
スクリプトファイルの実行
MariaDBコンソールからの実行
対象ファイルをドラッグ&ドロップすることで自動的にファイルパスが入力される
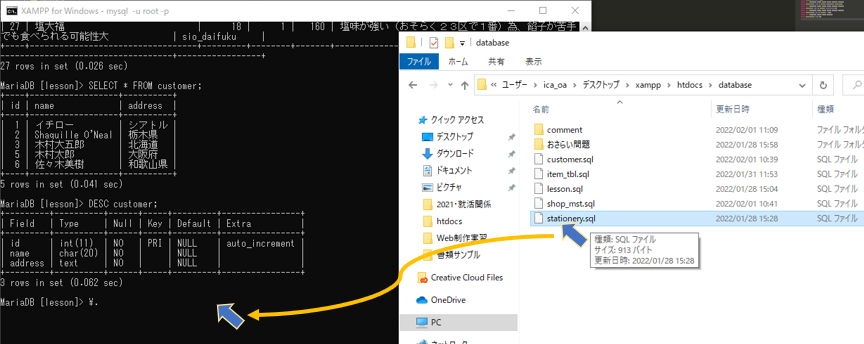
\. C:\Users\ica_oa\Desktop\xampp\htdocs\database\stationery.sql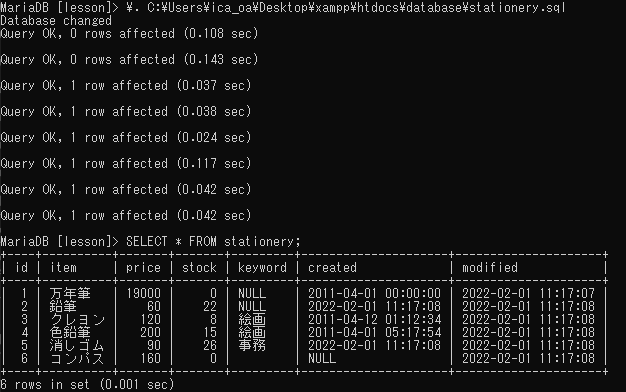
問題6:テーブルをスクリプトファイルを使って作成
-- 問題6
-- Windowsコマンドプロンプトから読み込ませる場合は文字コードを
-- 「Shift-JIS」にする
-- phpmyAdminやMacから読み込ませる場合は
-- 「UTF8」にする
-- 事前準備
-- DB領域選択
-- (間違ったDB領域にテーブルを作成しないように注意)
#データベース領域の選択
USE lesson;
#テーブルの削除
DROP TABLE IF EXISTS trader;
# stationeryテーブルの作成
CREATE TABLE trader (
id INT AUTO_INCREMENT PRIMARY KEY,
company CHAR(10) NOT NULL,
address TEXT NOT NULL,
tel CHAR(13) --INT型にしていると先頭の「0」が消えてしまう
);
#レコードの追加
INSERT INTO trader (company, address, tel)VALUES
('東京パン','東京都','03-0000-0000'),
('宇都宮米店','栃木県','028-111-1111'),
('札幌農場','北海道','011-222-2222'),
('浦安製菓','千葉県','047-XXX-3333'),
('ハイサイパン','沖縄県','098-444-XXXX'),
('出雲ファーム','島根県','0853-55-5555');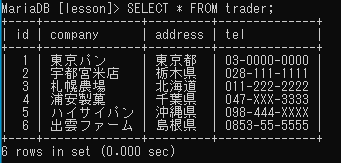
条件を付けて検索する
WHERE
比較演算子を使う
文字列の時は「’」「”」
「~と同じ」
「~以上」
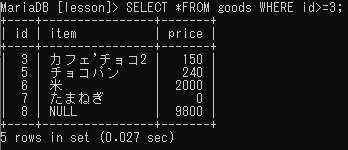
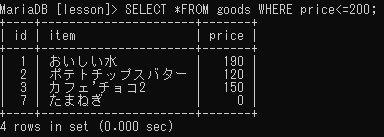
「~以下」
「~ではない」
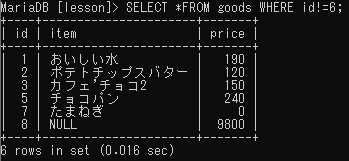
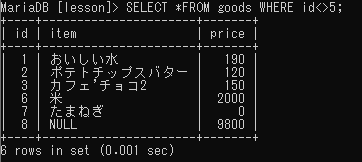
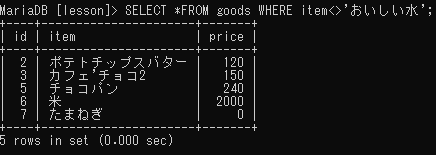
※検索フィールドに「NULL」がある値は除外される
「NULL値」、「NULL値ではない」
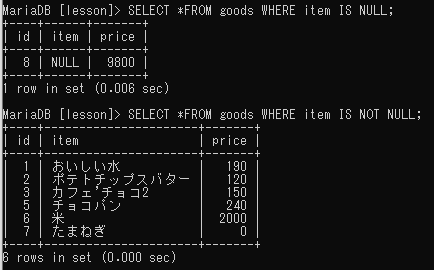
NULL値とは?
データが何も入っていないという意味。空文字(“”)が入っている場合は空文字というデータが入っているのでNULL値はない。
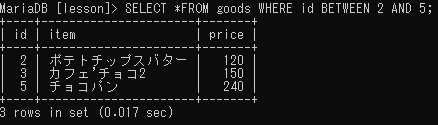
範囲
BETWEEN
値の範囲を指定して検索することができる。
WHERE フィールド名 BETWEEN 値 AND 値;英語のbetween A and Bは「AとBの間」という意味だが、SQL文では「A以上B以下」という意味になる。
条件を組み合わせる
AND/OR/NOT
複数の条件をすべて満たす検索(AND)
WHERE 条件1 AND 条件2;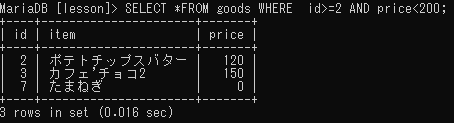
複数の条件のどれかを満たす検索(OR)
WHERE 条件1 OR 条件2;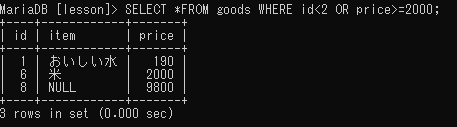
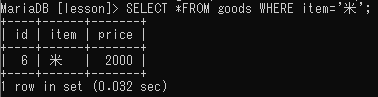
同じフィールドに対して複数の値を指定する
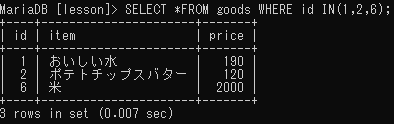
<SELECT *FROM goods WHERE id=1 OR id=2 OR id=6>
条件を反転させる(NOT)
WHERE NOT 条件;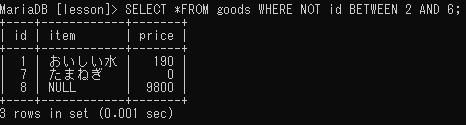
部分一致検索
LIKE
部分一致検索は「キーワード検索」とも呼ばれ、指定したキーワードを含んだレコードが検索される。
WHERE フィールド名 LIKE 部分一致検索文;LIKEの後に部分一致検索文を指定する。
部分一致検索文は対象となるキーワードとあいまい部分を表す記号を組み合わせて作成する。
任意の文字列をあらわす「%」
「%」は0文字以上に任意の文字列をあらわす記号。この「%」とキーワードを組み合わせて部分一致検索を行う。
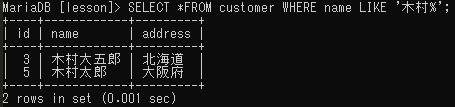
前方一致
部分一致検索文を’キーワード%’とすることで、前方一致検索を行うことができる。例えば苗字「木村」のレコードを検索したい・・・という場合に使用する。
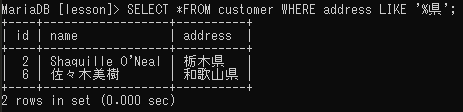
後方一致
部分一致検索文を’%キーワード’とすることで、後方一致検索を行うことができる。例えば住所「県」で終わるレコードのみ検索したい・・・という場合に使用する。
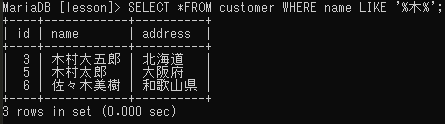
部分検索
値の中にキーワードが含まれているデータを検索する場合は「’%キーワード%’」という部分一致検索文を使う。キーワードの前後に0文字以上の任意の文字列があるレコードが対象になる。
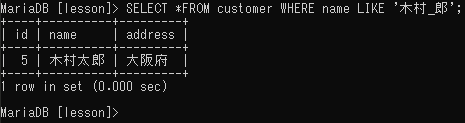
任意の1文字をあらわす「_(アンダースコア)」
例えば「木村_郎」は「木村太郎」や「木村次郎(今回のレコードにはない)」にはマッチするが「木村大五郎」にはマッチしない。あいまい部分の文字数がわかっている場合にすようするとよい。
「%」を含む文字列や「_」を含む文字列を検索
「%」「_」を含む文字列を検索する場合はエスケープ文字「¥」を使う。「¥%」と書けば「%」、「¥_」と書けば「_」を表す。例えば「_」を含むレコードを検索する場合は以下のようになる。
SELECT * FROM goods WHERE item LIKE '%¥_%'エスケープ文字自体を検索する場合は「¥¥」と記述することで「¥」を表す。
正規表現による検索
REGEXP
※日本語で使うとバグが多いので、今回は学ばない。
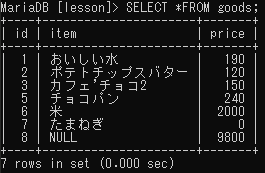
検索件数の制限
LIMIT
例えばランキングの上位5件のみ表示をする際などに利用する。
goodsテーブル内の条件に合うレコード5件だけを抽出する。
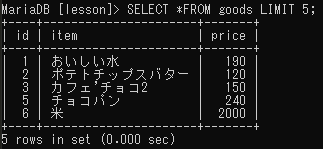
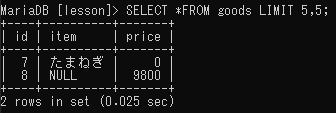
開始行と検索件数の指定
SELECT フィールド名 FROM テーブル名 LIMIT 開始位置,検索件数;2ページ目以降を表示したい場合や、一覧の途中を表示したい場合は、LIMITの後に「開始位置, 表示行数」を指定する。注意しなければならないのは開始位置が0から始まる点。「0」が1行目、「1」が2行目・・・となる。
| 開始位置 | id | item | price |
|---|---|---|---|
| 0 | 1 | おいしい水 | 190 |
| 1 | 2 | ポテトチップスバター | 120 |
| 2 | 3 | カフェ’チョコ2 | 150 |
| 3 | 5 | チョコパン | 240 |
| 4 | 6 | 米 | 2000 |
| 5 | 7 | たまねぎ | 0 |
| 6 | 8 | NULL | 9800 |
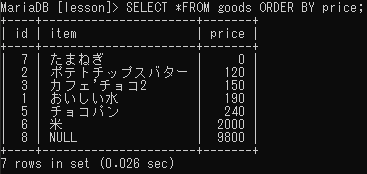
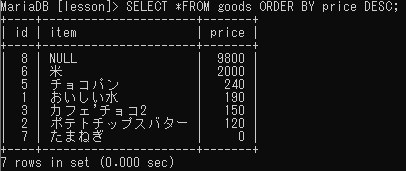
並べ替え
ORDER BY
ランキング表示や最新情報の検索などで活躍する。
ORDER BY フィールド名;goodsテーブルを価格順に並べ替えるSQL文は次のようになる。
降順にソートする場合はフィールド名の後に「DESC」と記述する。
DESCは降順を意味するdescendingを短縮したもの。
SQLの記述順
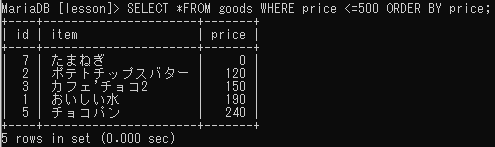
◆問題:価格500円以下の商品を安い順に表示


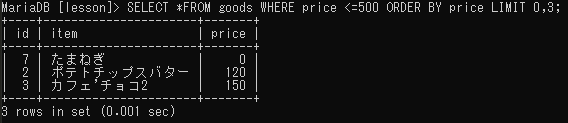
さらに、上位3件を表示
計算や集計
DBは計算や集計機能も備えている。goodsテーブルを使って確認をしていく。
合計値の出力(SUM)
SELECT SUM(合計値を出力するフィールド名)FROM テーブル名;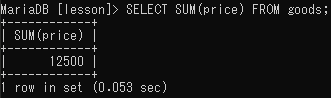
平均値の出力(AVG)
SELECT AVG(平均値を出力するフィールド名)FROM テーブル名;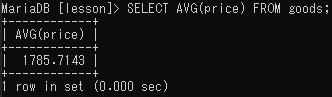
最大値の出力(MAX)
SELECT MAX(最大値を出力するフィールド名)FROM テーブル名;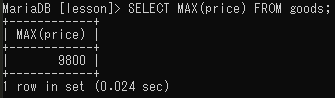
最小値の出力(MIN)
SELECT MIN(最小値を出力するフィールド名)FROM テーブル名;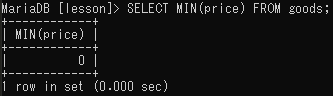
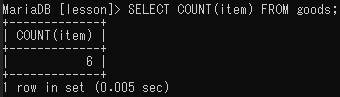
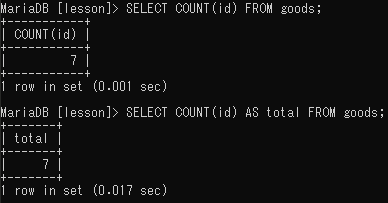
該当件数を取り出す(COUNT)
SELECT COUNT(該当件数を出力するフィールド名)FROM テーブル名;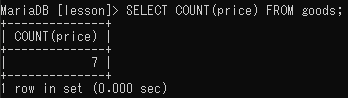
ただしNULL値は該当件数に含まれないので注意が必要。itemフィールドを使て該当件数を出力するとNULL値をもつレコードがカウントされず「6」となる。
フィールドに別名をつける(AS)
SELECT フィールド名 AS 別名 FROM テーブル名;「AS」を使用すると表示されるフィールド名を別名にすることができる。
問題9:商品名を指定して合計値を出力

問題10:金額範囲を指定して商品数を出力

NULL等が入らないようにCOUNTはプライマリーキーが適用されているフィールド名(id)を指定するのが良い。
データをグループ化する(GROUP BY)
※コレは飛ばす。